Using ForecastOS and InvestOS For Quant Investing: So Easy, an Intern Can Do It
Welcome to Weekly Roundup #20 at ForecastOS! We're glad to have you here, following our journey :) Note: this article was written by our summer intern, Callum Baker; we hope you enjoy it!
Hello ForecastOS subscribers!
My name is Callum, I am a mathematics and engineering student at Queen’s University, and I was an intern at ForecastOS during the summer of 2024. During this time, I trained various machine learning (ML) models for predicting returns in the stock market.
Despite being new to quantitative finance and data science, I was able to easily build an ML-driven systematic investment strategy that generated good returns with InvestOS and ForecastOS, in a fashion similar to the below demo:
So how did I manage to do this with little to no experience? I'll attempt to answer that below in the following order:
- My Definition of Machine Learning
- Data / Feature Engineering; 80% of the Work
- ForecastOS FeatureHub; Removing 80% of the Work
- The ML Algorithms I Tried
- Portfolio Engineering; Using InvestOS to Backtest My Performance
- Closing Thoughts
1. My Definition of Machine Learning
To get everyone on the same page, let me first attempt to define machine learning:
Machine learning is teaching a computer how to learn from (data) examples.
Imagine you’re teaching a friend how to tell the difference between cats and dogs. You show them lots of pictures of cats and dogs, pointing out differences until they can do it on their own. In machine learning, we give a computer lots of structured example data (like pictures of cats and dogs, or stocks and associated returns) and help it learn patterns so it can figure things out by itself, even with new examples it hasn’t seen before!
Raw data --> structured data (i.e. features) --> ML forecasts (e.g. stock return predictions)
2. Data / Feature Engineering; 80% of the Work
As the old adage goes, garbage in, garbage out.
The hardest part of ML / AI forecasting is correctly structuring data to feed ML / AI forecasting models. It's challenging and time-consuming to ensure data engineering logic properly handles lookahead bias, third-party data errors, etc.
If you are anything like me, you aren't a data engineering or finance expert.
However, despite this, my models were predictive. How could this be so, you might ask?
3. ForecastOS FeatureHub; Removing 80% of the Work
I had access to ~1,500 pre-engineered features directly from ForecastOS FeatureHub. I directly imported these ready-to-go features and could instantly start training my models!
It couldn't have been easier to get started; example code to import a feature below:
import os, forecastos as fos
fos.api_key = os.environ.get("FORECASTOS_KEY")
df = fos.get_feature_df(
"97c4fb88-7d1d-4d54-aa3e-4aaac0ba771d"
)Using these features, it was trivial to generate good forecasts; I was able to immediately focus on making good predictions without the (admittedly very challenging) financial data engineering work required to do so!
4. The ML Algorithms I Tried
After selecting ~100 features to use for prediction - which I admittedly did by intuition vs additivity - I began training and testing models using the below ML algorithms.
The first model I tried was XGBoost, which is "an optimized distributed gradient boosting library designed to be highly efficient, flexible, and portable."
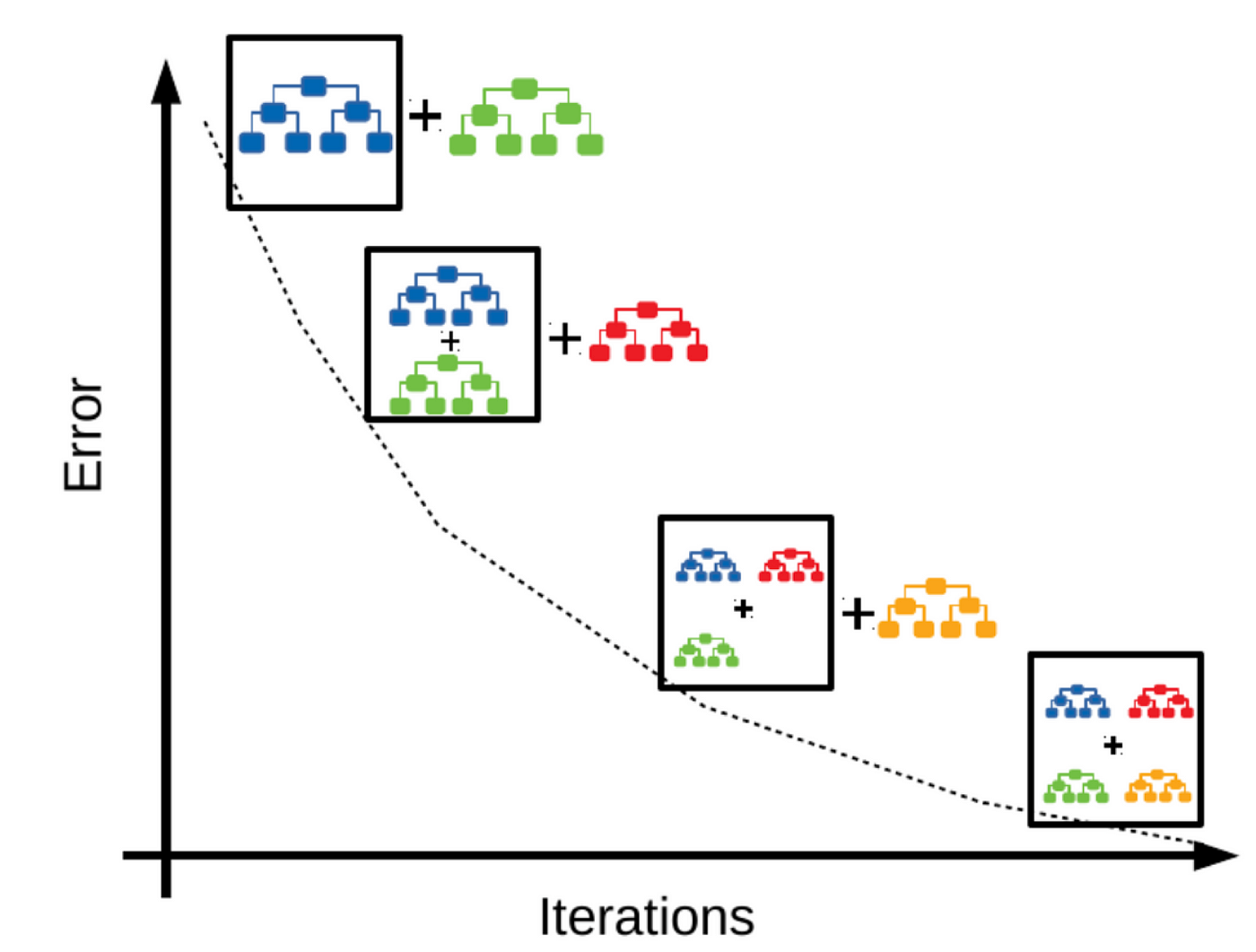
To put it simply, it performs a series of iterations, combining the newest iterations of decision trees with older iterations to reduce overall error. Said another way, imagine you’re building a LEGO tower, but instead of building it all in one go, you add just one small piece at a time, making it taller and better with each new piece.
Boosting in XGBoost is like that! It starts by building a tiny tree (or a mini decision) that isn't very good at getting the right answer. Then it makes another small tree, but this time, it learns from the mistakes of the first tree (note: including mistakes at a higher rate in following iterations is called boosting). Each new tree is like adding another LEGO piece, helping the whole structure get better and better until we have a really strong tower - or, in this case, a smart model that makes good predictions!
Using ForecastOS FeatureHub features and XGBoost hyperparameters (i.e. settings that control ML algorithm learning behaviour and accuracy), I trained, tested, and tweaked my model for predictive accuracy.
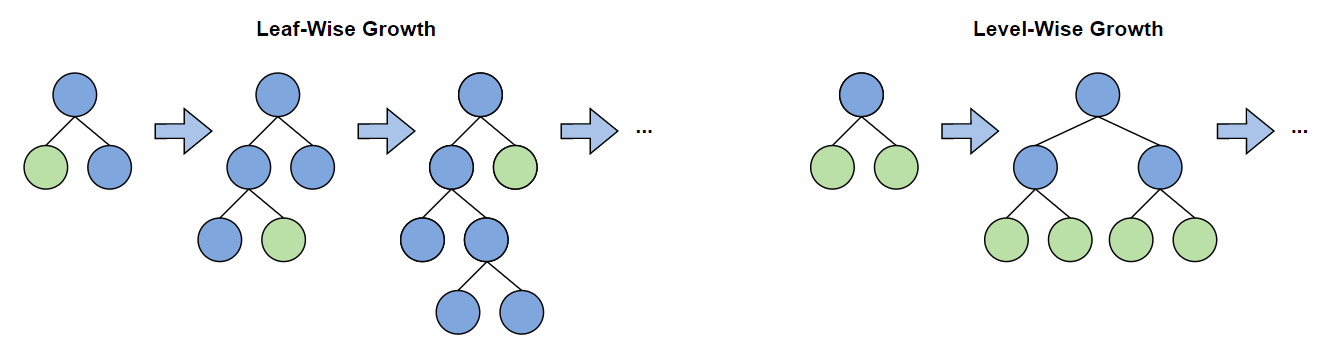
The second model I tried was LightGBM. It's similar to XGBoost (it is also a tree-based gradient boosting model), but it benefits from not requiring balanced trees, allowing for leaf-wise tree growth. This allows trees used by the model to grow deep off of a single node if deemed advantageous by the training algorithm. LightGBM otherwise has similar parameters to XGBoost for tuning how learning occurs.
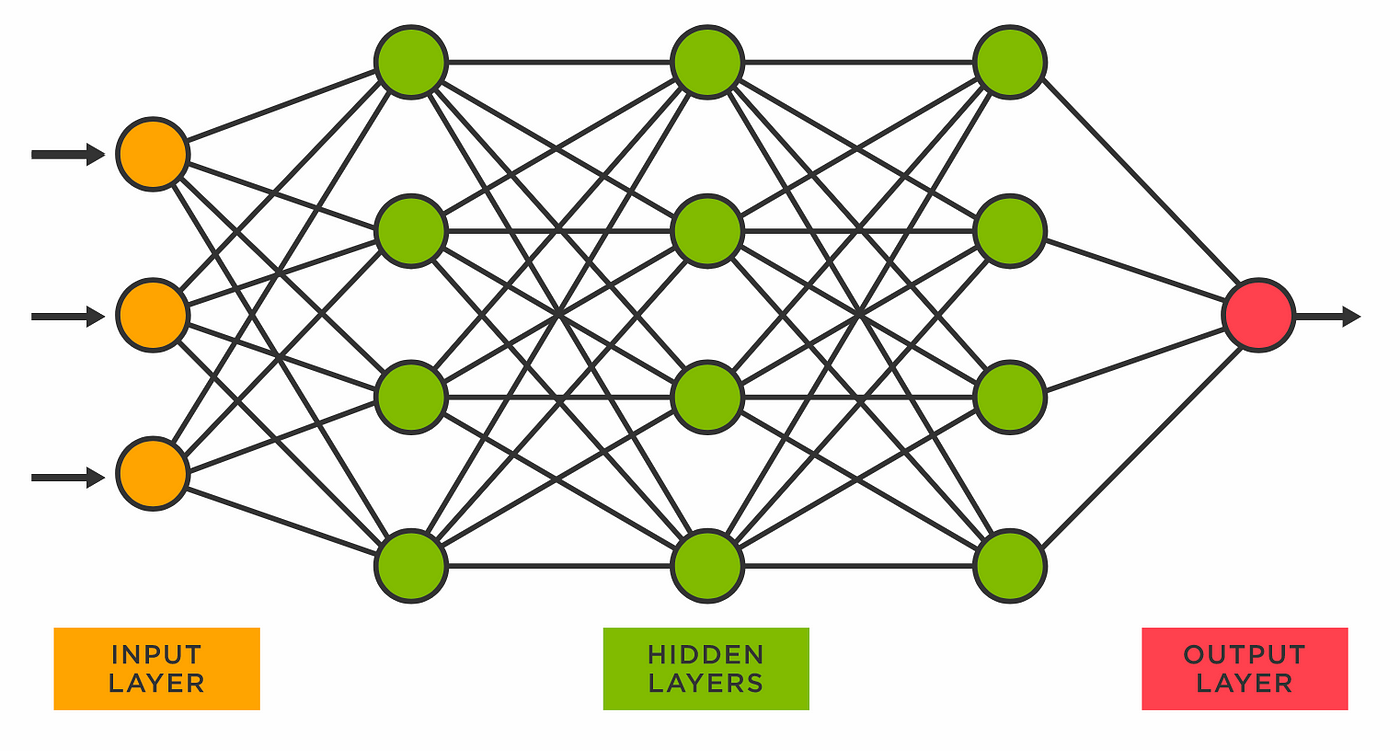
It is worth mentioning that I also tried a TensorFlow neural network. Despite sounding different, neural nets operate somewhat similarly to decision trees.
However, instead of having a terminal node / output, neural nets have a gradient of outputs that allows data to follow a larger variety of paths through the net. This allows for more complexity and models diffuse relationships well, like a brain... which I learned isn’t always a good thing.
While neural nets are great at
- learning to (iteratively) output sensible text tokens in response to a prompt (e.g. ChatGPT / LLMs),
- transcribing audio,
- or identifying an image,
they struggle to predict simpler things.
So which ML algorithm worked best?
In my experiments this summer, it was more/less a tie between LightGBM and XGBoost. As aforementioned, the neural nets were not quite suited for the job; they were very quick to overfit the problem.
Note: I also briefly tried random forests, but they lacked the gradient boosting functionality LightGBM and XGBoost seemingly benefitted from.
5. Portfolio Engineering; Using InvestOS to Backtest My Performance
To showcase my predictions in action, here is the return evolution I got when I converted my return forecasts to portfolios using InvestOS (for a market and factor neutral US-equities systematic strategy with sensible defaults and simulated holding and trading costs):
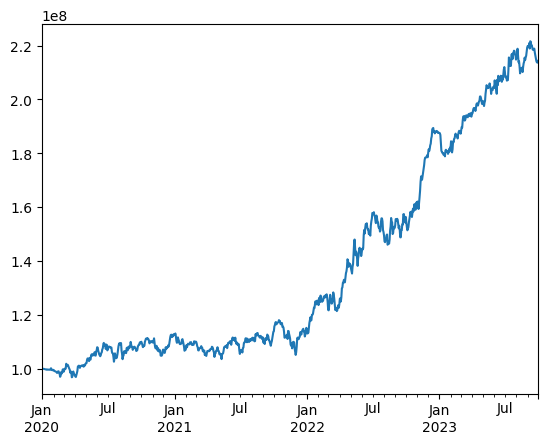
# Total portfolio return (%) 114.3%
# Annualized portfolio return (%) 22.59%
# Annualized excess portfolio return (%) 19.95%
# Annualized excess risk (%) 13.54%
# Information ratio (x) 1.47x
# Annualized risk over risk-free (%) 13.54%
# Sharpe ratio (x) 1.47x
# Max drawdown (%) 10.94%
# Portfolio hit rate (%) 55.07%6. Closing Thoughts
I hope my shared experiences from this summer interested you as much as it did me.
If you have any questions about anything above, or want to further discuss my work, you can reach me at [email protected] or ForecastOS at [email protected]
Cheers!